

本笔记是博主在学习C语言期间记录,涵盖了从C语言基础语法、数据类型、运算符、流程控制,到指针、复合数据类型、常用库函数以及数据结构基础的核心知识点。
编译与程序运行
一个C程序从源代码到执行需经历编译、链接、运行三个核心步骤。
![图片[1]-C语言核心知识笔记整理-萝莉猫博客](https://www.luolimao.com/wp-content/uploads/2026/02/20260228115429277-编译.png)
基本语法元素
转义字符
| 转义字符 | 意义 |
|---|---|
| \’ | 单引号(‘) |
| \” | 双引号(“) |
| \? | 问号(?) |
| \\ | 反斜杠(\) |
| \a | 警告 |
| \b | 退格 |
| \f | 换页 |
| \n | 换行 |
| \r | 回车 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \O00 | 八进制字符(o为八进制数) |
| \xhh | 十六进制字符(h为十六进制数) |
变量定义
定义变量的标准流程:
- 定义:指定数据类型和变量名。
- 初始化:给变量赋初值。
- 运算:对变量进行计算或赋值。
函数名,参数名,变量名不能以数字,下划线开头都可以随便起,函数名不能重复。
#include "stdafx.h"
int fun(int a,int b)
{
int c;//定义
c = 0;//初始化
c = a + b;//计算
}
int main(int argc, char* argv[])
{
fun(1,2);
printf("Hello World!\n");
return 0;
};结尾,;代表一条语句。数据类型及其范围
![图片[2]-C语言核心知识笔记整理-萝莉猫博客](https://www.luolimao.com/wp-content/uploads/2026/02/20260228121918457-C语言-数据类型.png)
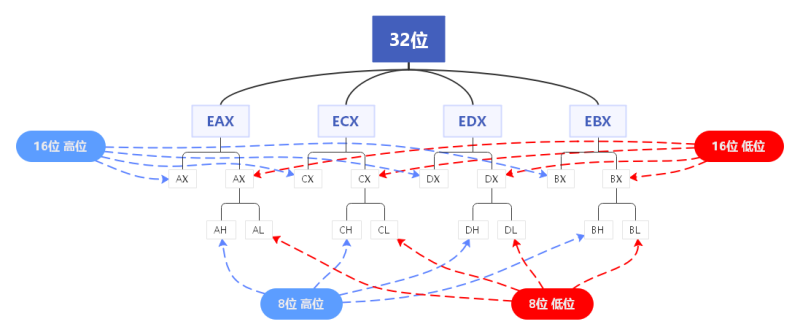
整型
在常见编译环境(如VC6)中,数据类型的内存占用和表示范围如下:
| 类型 | 字节数 | 取值范围 |
|---|---|---|
| int | 2 (早期) 或 4 | -32768 ~ 32767 或 -2^31 ~ (2^31-1) |
| unsigned int | 2 或 4 | 0 ~ 65535 或 0 ~ (2^32-1) |
| short | 2 | -32768 ~ 32767 |
| unsigned short | 2 | 0 ~ 65535 |
| long | 4 | -2^31 ~ (2^31-1) |
| unsigned long | 4 | 0 ~ (2^32-1) |
| long long | 8 | -2^63 ~ (2^63-1) |
| unsigned long long | 8 | 0 ~ (2^64-1) |
浮点类型
| 类型 | 字节数 | 有效数字 | 数值范围(绝对值) |
|---|---|---|---|
| float | 4 | 6 | 1.2×10^-38 ~ 3.4×10^38 |
| double | 8 | 15 | 2.3×10^-308 ~ 1.7×10^308 |
| long double | 8 / 16 | 15 / 19位 | 同上 / 3.4×10^-4932 ~ 1.1×10^4932 |
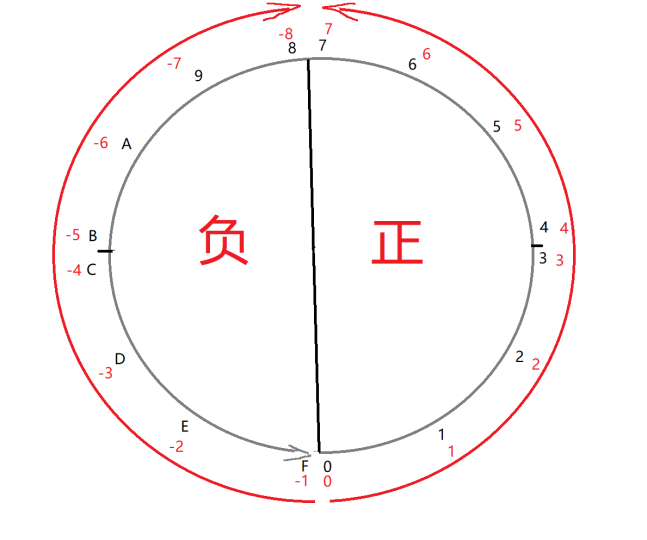
字符型
| 类型 | 字节数 | 取值范围 |
|---|---|---|
| signed char | 1 | -128 ~ 127 |
| unsigned char | 1 | 0 ~ 255 |
运算符分类
- 算术运算符:
+-*/%++-- - 关系运算符:
><==>=<=!= - 逻辑运算符:
!&&|| - 位运算符:
<<>>~|^& - 赋值运算符:
=及扩展运算符(如+=) - 条件运算符:
? : - 逗号运算符:
, - 指针运算符:
*(解引用)&(取地址) - 求字节数运算符:
sizeof - 强制类型转换运算符:
(类型) - 成员运算符:
.-> - 下标运算符:
[ ] - 函数调用运算符:
( )
表达式:用运算符连接起来的式子。
流程控制语句
判断语句
if语句:主要判断阔号里表达式是否成立,如果为0表示不成立。在反汇编里面跳转位置反着来的,括号里面的表达式的判断条件是反过来的
if(表达式) //如果 if
{
//语句---》以分号结尾就叫语句
}if…else语句:else相当于jmp指令跳转 (跳到if外面)
if(表达式)//如果
{
//语句
}
else//否则
{
//语句
}if…else if…else语句:可用于实现多路分支
if(表达式) //如果 if else if
{
语句
}
else if() //否则 如果
{
语句
}
else //否则
{
语句
}
//如果if 条件成立跳走,如果if不成立,执行 else ifswitch…case语句:用于多分支选择,编译器会根据case值的连续性和数量,生成跳转表或进行二分查找等优化。break用于跳出整个switch块,default相当于else。
switch(表达式) //switch会多分配4个字节用于存放阔号中表达式的结果,用于比较
{
case 0:
{
break; -->相当于JMP 结束Switch
}
default ---> 相当于else
}if…else if…else转化switch…case方法:
- 必须是 == 表达式。
- 等号的左边必须是 相同的表达式。
- 等号的右边 必须是常量,而且常量要互不相同。
switch判断比较位置:
- 如果
case从0开始直接比较最大的case数。 - 如果不是0开始要先减去最小的
case数变成从零开始,然后在比较用最大的case数减去最小的case数 做比较。
switch的几种情况:
case数连续性的,会在内存里建一张(case地址表),里面会存放case的地址通过内存地址加ecx*4偏移的方式,寻找case的位置,没有的case数,用default的地址填充。(4个case才建表不然直接进行比较)case数相对连续的,会在内存里建立两张表,第一张是case的编号表(索引表),从0开始。如果没有的case,会填充case的个数,对应default的位置,第二张表,记录case的地址,用case的编号加上case的地址(通过内存地址加ecx*4偏移的方式寻找case地址表),找到case的位置(8个case才建两张表case编号表和case地址表不然就建一张case地址表)case数毫无规律的直接判断进行比较,比较方式为二分法(编辑器自动排序)- 综合前面三种。
运算与比较:
算术运算:跟零比较,为零不成立,不为零成立。
- 使用
CMP指令—>SUB,结果丢弃影响标志位。 - 使用
TEST指令—>AND,结果丢弃影响标志位,清零(CF、OF标志),设置PF、SF、ZF(位与位之间运算)。
关系运算:使用CMP指令,条件成立执行,条件不成立不执行。
判断条件的时候如果是零的话比较特殊有可能是用cmp有可能用test如果跟零比较通常用test 当然也会用到cmp。
汇编层面(|| 、&&):
|| 或者,先判断第一个条件,如果成立,后面的条件不执行,所以这个判断条件在反汇编指令就正着来的
&& 并且,在反汇编里,跳转的地址一样,并且两个或者多个表达式要同时成立
汇编层面分辨if、if...else、if…else if…else方法:
- 只要判断
if的跳转位置他的上方有没有jmp语句 如果有代表有else如果没有代表只有if语句 - 如果只有判断条件说明是
if语句 如果有判断条件,判断条件上方还有1个jpm说明是else if语句 - 如果只有一个
jmp说明是else语句
汇编层面查看if、if...else、if…else if…else范围:
if else如何查看范围 主要看else的跳转位置if语句如何查看的范围 直接看if的跳转位置 如果跳转的上方没有jmp指令 那么上面这一段就是if表示范围
循环语句
while语句:先判断条件,后执行循环体。本质上等价于if+goto。
while循环阔号表达式可以是算式运算可以是关系运算。
- 算式运算一定要注意容易造成死循环,要加上
break。 - 关系运算看表达式结果,看条件成不成立。
- 在反汇编层面
while循环要看他往回跳的位置来确定整个循环的范围
goto相当于汇编jmp指令 (需要leb标签)
while(表达式)//---> 相当于 if 加 goto语句
{
//语句
}while语句三要素:
- 表达式用关系表达式,表达式关系必须成立
- 判断条件的成员,必须做运算,当作结束循环的条件。
- 判断条件的成员,不能保存结果。
do while语句:先执行一次循环体,再判断条件。在汇编层面判断条件与源码一致
do
{
//语句
}while(表达式); //后面有个分号while和do…while语句区别:
while:先判断条件,后执行循环体。
do while:先执行一次循环体,再判断条件。在汇编层面判断条件与源码一致。
for语句:包含初始化、条件判断、增量更新三个表达式。分析汇编时,观察跳回的位置可以确定循环体范围。
for(表达式1;表达式2;表达式3)//3个表达式,可以没有,可以都存在,可以只有其中一个
{
//语句
}for语句三个表达式:
- 初始化循环变量。
- 设定循环条件(通常为关系表达式)。
- 在循环体内更新循环变量(通常自增、自减)
循环嵌套:二层循环(循环嵌套)外层循环一次 内嵌循环全部执行
while和for之间转换:
while( a <= 100)
{
b= b+a;
a++;
}
for(; a <= 100; )
{ b= b+a;
a++;
} 复合数据类型
数组
int a[10];//类型 数组名字[常量];
int--> 类型 a-->数组名字 []-->常量 代表数组的大小什么是数组:数组把相同类型变量放到一起。
特点:元素下标从0开始。数组名代表首地址。在内存中,数组元素常按逆序(从高位地址到低位地址)存放。
数组的变量名就是数组的地址,数组第1个成员取地址也是数组的首地址。
如何看变量类型:直接去掉变量名就是它类型。
数组定义三要素:
- 数组大小
- 数组从0开始
ESP减多少(vc6默认0x40 + 数组大小)
sizeof 测试类型的大小:
//sizeof 例子
#include "stdafx.h"
int main(int argc, char* argv[])
{
int a;
a = 10;
printf("%d\n",sizeof(a));
return 0;
}数组偏移量计算:
- 标准写法:数组的大小*数组的类型 – 数组成员*数组的类型 = 数组偏移的位置(注意对齐情况)
- 演变写法:(数组的首地址偏移-数组偏移) * 数组类型(注意对齐情况)
- 下标写法:ebp -(数组最大-数据下标)* 数组的类型
如果计算数组偏移时出现没有对齐的情况要自动对齐 先对齐在计算
int fun()
{ //esp-0x68
int a[10];//esp-0x28
a[0] = 1;//esp-0x28
a[1] = 2;
a[2] = 3;
a[3] = 4;
a[4] = 5;
a[5] = 6;// 4 * 10 - 5 * 4 (10 - 5) * sizeof(int)
a[6] = 7;
a[7] = 8;
a[8] = 9;
a[9] = 10;
return 0;
}多维数组:
int a[2][5]; //比如有 2个班,每个班5个学生
int a[3][2][5]; //比如 有3个年级 2个班,每个班5个学生
int a[4][3][2][5]; //比如 有 4个学校 3个年级 2个班,每个班5个学生 以此类推多维数组偏移计算例子:
计算偏移的时候,如果没对齐,先对齐,然后用对齐的结果去减
int a[2][5];//esp-0x68 ebp-0x28
//比如计算 a[1][1] 的偏移 2*5*4 - (1*5*4 + 1*4) (2*5 - 1*5+1)*4 先算出第1个成员的1*5*4 然后第2个成员就是他的值×4
//a[1][1] //-->1*5*4 + 1*4 (1*5+1)*4 ebp-0x28 + (1*5+1)*4
int b[10][5];//esp - 0x108 ebp - 0xc8
//b[6][3] = 1; (6*5 + 3)*4=0x84 ebp + (0x c8-0x84)
int b[8][6][7];//esp-0x580 ebp-0x540
//比如计算 a[6][3][4] 的偏移 8*6*7*4 - (6*6*7 + 3*7 + 4)*4 = 0xec
int a[7][8][6][5];
//比如计算 a[3][2][4][1] 的偏移 7*8*6*5*4 - (3*8*6*5 + 2*6*5 + 4*5 + 1)*4
int b[2][5][4][8];//esp-0x540 ebp-0x500
//比如计算 a[1][2][3][4] 的偏移 2*5*4*8*4 - (1*5*4*8 + 2*4*8 + 3*8 + 4)*4 = 0x110多维数组反推数组数量:
int fun()
{
int a[8][6][4][5];
int i;
int j;
int k;
int m;
//0xF00
//i --> 0x1E0
//j --> 0x50
//k --> 0x14
m*4
k*5*4 = 0x50
j*4*5*4 = 0x1E0
i*6*4*5*4 = 0xF00
//倒推
m*4 = 0x14 //0x14 ÷ 4 得到k数量 因为5×4=14 16进制
k*m*4 = 0x50 //0x50 ÷ 0x14 得到k数量
j*k*m*4 = 0x1E0 //0x1E0 ÷ 0x50 得到j数量
i*j*k*m*4 = 0xF00 //0xF00 ÷ 0x1E0 得到i数量
//a[i][j][k][m]; m=5 k=4 j=6 i=8
for (i = 0; i < 8; i++)
{
for (j = 0; j < 6; j++)
{
for (k = 0; k < 4; k++)
{
for (m = 0; m < 5; m++)
{
a[i][j][k][m] = k++;
}
}
}
}结构体 (struct)
struct 结构体名 //struct 是关键字
{
//类型名 成员名;
char a;
short b;
char c;
};结构体是什么:不同类型变量放在一起,然后生成新的类型。
结构体名字是结构体首地址,第一个成员的地址也是结构体首地址。
- 结构体的访问方式是打点访问 (.)。
- 结构体套结构体 把被套变量放下结构体下面。
- 结构体套结构体 有几个结构体就有几个点。
怎么算结构体成员变量的位置:
用结构体的首地址 – 结构体成员变量的类型(注意对齐情况)
结构体成员变量中,char类型下面,只要不是char,都要考虑对齐情况
结构体偏移计算方式:
计算结构体偏移的时候,要先查看对齐情况,用结构体首地址的偏移,减去前面的类型,尤其需要注意short的类型情况的对齐方式。
共用体 (union)
union 共用体名 //union 关键字
{
char a;
short b;
int c;
};共用体定义:所有成员共享同一段内存空间。
- 如何判断类型所占空间大小直接看最大的数据类型,就是占多少字节
- 共用体就是共用同一个内存
枚举 (enum)
enum em //enum 关键字
{
one, // 从0开始
two,
tt = 8,
hh = 1,
gg
};枚举定义:用于定义一组命名的整型常量。
- 枚举从0开始依次递增,可以赋值,然后依次递增(枚举相当常量)占固定4个字节空间
- 占4字节,把枚举当成常量,从0开始,依次递增,(中间可以修改然后依次递增)
位段
struct bit //位段
{
char a:2; //低位
char b:3;
char c:3; //高位
};位段定义:允许在结构体中按位为单位来指定其成员所占内存长度。
- 定义前面的是低位,后面的是高位。
- 定义无符号类型
位段运算的时候,先用and用来给目标清零(初始化FFFFFFFF看你4个字节还是2个字节还是1个字节,如果1个字节的话初始化8个1然后是你清哪位就是哪位),然后用OR给目标赋值(还是看你是哪位低两位还是低三位还是中间两位还是高五位)
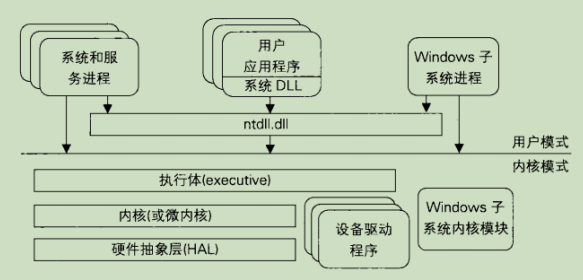
指针
指针是C语言的核心特性,存储的是内存地址。
指针变量
int* p; // *号就代表指针 p代表指针地址 *p代表指针里面得值- 基本概念:
int* p;中p是指针变量(存放地址),*p是该地址处的值。
- 是指针都占四个字节
- 只要是指针,就得给地址(有效的地址)
- 指针自增自减的时候, 去掉变量名在去掉星号(*) 看前面类型是多少,就加多少或者减多少
- 在变量得前面加上类型就是强制转换
- 给指针赋值 只要是指针就要给地址,赋到不是指针为止
int a,b;
int** p;
p = (int**)&a;
*p = (int*)&b;
**p = 1;- 1个&符号就代表一个(*)星号
- *p 取地址(内存)里面的值
- 在反汇编里面一颗星( * )代表一个方括号( [ ] )
两个指针相减代表是有符号的,先用两个操作数相减,减完后在用结果除以 去掉变量名在去掉一个星号( * ) 看前面什么类型是多少就是多少。(相同类型指针才能相减)两个指针比较是无符号的。
什么是强制转换:
在变量前面加上(目标类型)里面填要转换的类型,用于改变对同一片内存数据的解释方式。
int a,b;
int** p;
p = (int**)&a;//强制转换
*p = (int*)&b;
**p = 1;指针与数组
数组名可视为常量指针。*(p+i)等价于 p[i]等价于 a[i]。
int* p;
int a[5];
p = a;
*p = a[0];
*(p+0) = a[0];
p[0] = a[0]
----------------------------------------
int** p;
int a[2][2];
int b;
p = (int**)&b;
*p = (int*)a;
(*p)[0] = a[0][0];指针类型辨析:
- 指针数组:本质是数组,元素是指针。如
int* p[5];。
int*****p[5][4];//指针数组
//p 类型--->int***** [5][4] 5*4*4=80 占80字节
//*P 类型--->int***** [4] 4*4=16 占16字节
//**p 类型--->int***** 4 占4字节
//***p 类型--->int**** 4 占4字节
//****p 类型--->int*** 4 占4字节
//*****p 类型--->int** 4 占4字节
//******p 类型--->int* 4 占4字节
//*******p 类型--->int 4 占4字节
int******* p[5][4][3];//先把方括号去掉
//p 类型--->int******* [5][4][3] 5*4*3*4=240 占240字节
//*P 类型--->int******* [4][3] 4*3*4=48 占48字节
//**P 类型--->int******* [3] 3*4=12 占12字节
//***p 类型--->int******* 4 占4字节
//****P 类型--->int****** 4 占4字节
//*****p 类型--->int***** 4 占4字节
//******p 类型--->int**** 4 占4字节
//*******p 类型--->int*** 4 占4字节
//********p 类型--->int** 4 占4字节
//*********p 类型--->int* 4 占4字节
//**********p 类型--->int 4 占4字节- 数组指针:本质是指针,指向一个数组。如
int (*p)[5];,占4字节。
int (****p)[5][4]
//p 类型--->int (****)[5][4] 4 占4字节
//*p 类型--->int (***)[5][4] 4 占4字节
//**P 类型--->int (**)[5][4] 4 占4字节
//***p 类型--->int (*)[5][4] 4 占4字节
//****p 类型--->int [5][4] 5*4*4=80 占80字节
char*** (*****p)[5];
//p 类型--->char*** (*****)[5] 4 占4字节
//*p 类型--->char*** (****)[5] 4 占4字节
//**P 类型--->char*** (***)[5] 4 占4字节
//***p 类型--->char*** (**)[5] 4 占4字节
//****p 类型--->char*** (*)[5] 4 占4字节
//*****p 类型--->char*** [5] 5*4=20 占20字节
//******p 类型--->char*** 4 占4字节
//*******p 类型--->char** 4 占4字节
//********p 类型--->char* 4 占4字节
//*********p 类型--->char 1 占1字节函数指针
指向函数的指针。可用于函数回调,只要函数原型(返回类型、参数列表)一致即可。
- 怎么看函数的原型:把函数名字去掉,就是函数原型
- 参数里面的(…)代表无限参数
- 调用约定
_cdecl外平栈,自己写的函数,默认是外平栈 (_stdcall内平栈)(_fastcall快速调用,寄存器传参)
typedef 给类型重新取一个别名:
//比如 strcpy
typedef char* (*pstrcpy)(char *, const char *); 定义函数指针类型
pstrcpy strcopy; //定义函数指针类型变量
strcopy = (pstrcpy)strcpy; //给函数地址
char str[10] ;
const char* src = "1234";
strcopy(str,src); //调用函数回调:
使用函数指针回调,必须保证函数的原型是一样
int add(int a,int b)
{
int c;
c = a + b;
return c;
}
int or(int a,int b)
{
int c;
c = a | b;
return c;
}
int xor(int a,int b)
{
int c;
c = a ^ b;
return c;
}
int fun(int (*p)(int,int)) //中间介
{
int ret;
ret = p(2,2);
return ret;
}
int main(int argc, char* argv[])
{
fun(add);//相同函数原型
fun(xor);//相同函数原型
fun(or);//相同函数原型
return 0;
}求出真正的函数地址方法:
用当前函数地址 + 5 + 后面四个地址的偏移 然后就求代码真正的位置
00401032 E9 39 03 00 00 jmp fun (00401370)
//计算函数地址:401032 + 5 + 0339 = 00401370
DWORD GetFunAddree(void* fun)
{
BYTE* p;
p = (BYTE*)fun;
if (*p == 0xe9)
{
p = p + 5 + *(DWORD*)p[1];
}
return (DWORD)p;
}结构体指针
结构体指针:使用 ->运算符访问成员。
常用库函数摘要
| 类别 | 函数名 | 函数功能简介 |
| 内存管理 | malloc | 动态分配指定大小的内存空间 |
| calloc | 动态分配内存,并初始化为零 | |
| realloc | 重新调整已分配内存块的大小 | |
| free | 释放动态分配的内存空间 | |
| 字符串处理 | memcpy | 从源内存地址拷贝指定字节到目标地址 |
| memcmp | 比较两段内存的前n个字节 返回值: str1>str2返回1 str1=str2返回0 str1<str2返回-1 | |
| memset | 将内存块初始化为指定值 | |
| strcpy | 复制字符串 | |
| strncpy | 复制指定长度的字符串 | |
| strcat | 拼接字符串(连接) | |
| strncat | 在字符串结尾追加指定长度字符串 | |
| strcmp | 比较两个字符串 返回值: str1>str2返回1 str1=str2返回0 str1<str2返回-1 | |
| strncmp | 比较两个字符串的前n个字符 | |
| strlen | 获取字符串长度(不计’\0’) | |
| strlwr | 将字符串转换为小写 (非标准/平台相关) | |
| strupr | 将字符串转换为大写 (非标准/平台相关) | |
| strtok | 字符串分割 | |
| strxfrm | 根据区域设置转换字符串,用于排序比较 | |
| puts | 输出字符串到标准输出(自动换行 | |
| gets | 从标准输入读取字符串(不安全,不推荐使用) | |
| 类型转换 | atoi | 将字符串转换为整型 (int) |
| itoa | 将整数转换为字符串(2-36进制)(非标准/平台相关) | |
| atof | 将字符串转换为双精度浮点数 (double) | |
| 数学运算 | abs | 求整数的绝对值 |
| pow | 计算x的y次幂 (x^y) | |
| sqrt | 计算给定值的平方根 | |
| 随机与系统 | rand | 取一个随机值 rand%多少,就是这个数的范围之内 rand%100 100以内 |
| srand | 给rand 提供一个随机种子 一般是以时间为伪随机数 | |
| time | 获取当前系统时间(通常用作seed) | |
| exit | 终止进程,关闭所有文件流 | |
| system | 执行一个操作系统命令 | |
| 字符I/O | getchar | 从标准输入读取一个字符 |
| putchar | 向标准输出写入一个字符 | |
| 文件操作 | fopen | 打开文件 |
| fclose | 关闭文件 | |
| fgetc | 从文件读取一个字符 | |
| fgets | 从文件读取一个字符串(最多n-1个字符) | |
| fputs | 向文件写入一个字符串 | |
| fprintf | 格式化输出到文件 | |
| fscanf | 从文件格式化输入 | |
| fread | 以二进制形式从文件读取数据块 | |
| fwrite | 以二进制形式向文件写入数据块 | |
| feof | 检测是否到达文件末尾 | |
| fseek | 重定位文件位置指针 | |
| ftell | 获取文件位置指针的当前位置(偏移字节数) | |
| ferror | 检查文件流的错误标志 | |
| clearerr | 清除文件流的错误和文件结束标志 |
数据结构与算法基础
数据结构:一堆数据的集合
核心三步骤:构建内存图初始化、填入数据、遍历/操作数据。
存储方式:
- 顺序存储:通常用数组实现,物理地址连续。
- 链式存储:通常用结构体指针实现,通过指针链接节点。
经典结构:
- 堆栈 (Stack):先进后出 (FILO)。
- 队列 (Queue):先进先出 (FIFO)。
递归:函数直接或间接调用自身
- 必须包含递归出口(终止条件)。
- 擅长处理非线性问题。



暂无评论内容